How to fix agile teams that are notoriously bad at hitting release dates | TechCrunch
Many of today’s best software companies tout agile development as a way to release software early and often, as longer-term planning can be more heavily impacted by project unknowns.
Yet why do IT projects using agile still consistently hit delays and exceed budgets? Our development team was able to triple productivity by looking outward for inspiration, and found that the project planning methods commonly used in non-IT engineering projects have the key to solving this problem. It’s called reference class forecasting.
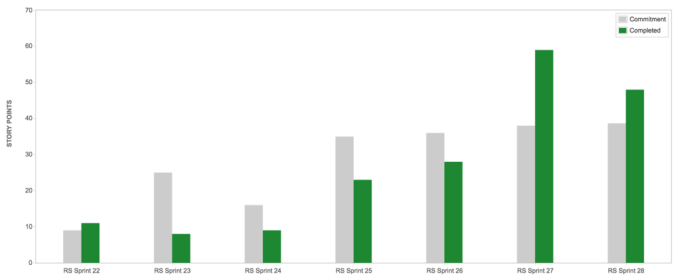
Source: On-Site.com. A velocity chart by one of the dev teams before and after the implementation of reference class forecasting. Each sprint represents two weeks. Sprints 23-26 represent feature shortages and release overshoots. In sprint 24, the team began incorporating reference class forecasting. Target overshoots were maintained since sprint 27.
As a consequence of better estimates and improved productivity, team morale and confidence markedly improved. But above all, the most important thing that reference class forecasting can teach is that we are naturally myopic, and consistently fail to account for dependence on people and technologies that live outside of the team. And, it helps us to deal with that problem in a systematic way. This article explains the theory and practice of applying this approach to agile development.
The problem with estimating development efforts
Oxford researchers Alexander Budzier and Bent Flyvbjerg published research in 2013 in which they found that agile methods appear to improve project delivery times. Yet, in the more than 4,000 IT projects they surveyed, the average schedule overrun was +37 percent , and the average cost overrun was +107 percent. Outliers that significantly exceed schedule or budget can tremendously impact business. They found that 12.8 percent of projects were twice as expensive as expected, and 12.6 percent were +90 percent behind schedule.
One problem is that the human brain’s forecasting capabilities are limited, leaving us prone to cognitive biases that lead to systematic errors of judgement. This bias tends to be overly optimistic rather than pessimistic regarding the amount of work required for projects. The use of “story points” does little more than foster overconfidence by suggesting an objective quantifiability which, in reality, is merely an illusion.
How can software managers and developers take estimation metrics (i.e. story points) seriously if they base them on intuitive predictions that are inherently prone to inaccuracy? While Scrum, for example, does not prescribe a single way to estimate efforts, different strategies have been developed within the agile development community to address this problem. Most prominent perhaps is the #NoEstimates movement, which aims to challenge the status quo and explore alternatives.
Common solutions and their shortcomings
One strategy to overcome estimation challenges relies on atomic user stories: all stories are made as small as possible to reduce complexity and variability in effort needs. The problem with that is that not all user stories are created equal, no matter how granular they are. They all have varying degrees of complexity, dependencies and unpredictable events affecting the actual effort required.
The greatest opportunity will lie in the sharing of information among the wider agile community.
Doing away with estimates altogether is a hasty approach, as well. They are useful to allocating limited resources, and the practice of collaboratively identifying uncertainties helps teams reduce blind spots and take constructive action in the face of uncertainty. Just abandoning workload estimations altogether out of frustration would lead us to ignore risk, making it even harder to contain.
Another strategy to tackle estimation uncertainty is simply to get more estimates. Instead of relying on the judgment of one developer, all team members are asked to hazard a guess, ideally simultaneously to avoid biases (often done through “planning poker”) and use that as a basis for further deliberations. However, no matter how large the group is, this approach still relies on intuitive prediction and is prone to biases such as groupthink.
Adopt an outside view
In 1979, Kahnemann and Tversky published a piece on intuitive prediction, in which they argue that “man suffers from mental astigmatism as well as from myopia, and any corrective prescription should fit this diagnosis.” They suggest to look beyond “singular information” and instead seek guidance in “distributional information.”
What do they mean? Singular information is what we know about an individual case. Take a doctor for example. If she looks at her patient’s individual characteristics (e.g. age, state of health and past medical history) to make a prediction about his health outcome, she uses singular information. Distributional information, by contrast, consists of “knowledge about the distribution of outcomes in similar situations.”
Here, a doctor would turn to data from relevant clinical trials and epidemiological studies to derive estimates for individual patients based on results of other cases with comparable characteristics, thus relying on much more ample evidence. The latter approach consists of adopting an outside view that does not attempt to divine a particular manner in which a plan might fail but asks “how long do such projects usually last?”
Reference class forecasting in agile development
Now — could the outside view help agile development teams with their predictions, too? Yes! Already, some teams make forecasts by comparing completed stories over time to those in the pipeline, which is a relatively straightforward way to derive value from existing data.
However, to improve forecasts we need to compare likes with likes. Merely reducing complexity by, for example, breaking up user stories into the smallest possible bits, keeping turnover of team members to a minimum and reducing external dependencies is not good enough. Individual user stories might be very different.
As your database of comparable cases grows, your predictive accuracy for building new product features will improve.
Imagine a project manager in charge of building a mountain road. If she would solely compare the costs and time per mile of all roads she built before, her estimates might be blurred because not all the roads she constructed are comparable: Highways are different from village roads and the construction environment also makes a difference (e.g. forest versus tunnel). Valuable comparisons can only inform her predictions if she has a database of comparable cases that are broad enough to generate adequately large sample sizes and are sufficiently narrow to be relevant. This is what other industries call reference class forecasting.
How do you define reference classes for agile software development?
One way could be for individual companies or teams to develop their own categorical tags and apply them both to completed and new backlog items. We have been experimenting with product feature tags and process feature tags to exhaustively capture the ways that a given feature involves complexity or dependencies on external factors or actors.
Product feature tags focus on what the planned feature does (e.g. “has a front-end user interface” or “connects ≥2 databases”) while process feature tags focus on what the product development team does to develop the feature. To provide an example, our team’s process feature tags are derived from asking the following questions during estimation:
- Does external dependency on other teams exist?
- Do we depend on code that does not rely on the same standards (e.g. Ruby on Rails, APIs)?
- Is research needed to complete a problem?
- Do we have to write tests?
- Are there interdependencies within the code base?
- Are we touching new territory in some other way?
These tags capture complexity and external dependencies in order to accumulate distributional information on the typical time and resource budgets that we see associated with each tag. Some tags work better in one setting than another (please share experiences your development team has had in the comments below). The tags used and overall approach can be modified iteratively through experimentation and adaptation, which fits the larger agile paradigm well. The key is to keep feature tags as simple as possible and to regularly evaluate and discuss the predictive value of each tag to keep adapting the list until a suitable set of classes is available.
Building a meaningful reference class database
As your database of comparable cases grows, your predictive accuracy for building new product features will improve. More can be done with your database, such as better identifying outliers: If a backlog item lies significantly outside the standard deviation of time needed for comparable backlog items, you could study these cases in depth to identify hypotheses about important influences in order to inform future practices. Additionally, you could identify positive deviants, high-performing teams or individuals compared to the average, and try to advance best practices based on their insights, assuming they are willing to share their thoughts.
If this seems at all convincing, then the residual question is: How do we build a reference class database? Small companies or individual teams can grow proprietary reference classes whose predictive estimation power will increase over time. Still, the greatest opportunity will lie in the sharing of information among the wider agile community, beyond corporate or individual borders.
The most obvious actors here would be providers of online agile management platforms (such as, for example, Atlassian) who already sit on vast data sets from various teams. Whatever the path, any move that nudges our natural bias toward adopting an outside perspective will help us understand that problems are rarely so unique that they cannot take lessons from others.
Featured Image: erhui1979/Getty Images
Dr. Sven Jungmann is an internationally trained medical doctor who speaks and consults on healthcare innovation and digitization.
Source: How to fix agile teams that are notoriously bad at hitting release dates | TechCrunch